agent_mode adds an intelligent orchestration layer to episodic long-term memory retrieval, moving beyond simple similarity to active reasoning. Use agent_mode=true in your memory search APIs to handle complex questions that require more than one step to answer.
How it Works
1
Smart Routing
The
ToolSelectAgent analyzes your query to decide the best path forward: a direct lookup, splitting the query into parts, or following a chain of evidence.2
Specialized Execution
The orchestrator hands the query to a specialized agent that can dig through your memory based on the specific complexity of your question.
3
Evidence Aggregation
MemMachine gathers all the findings, reranks them for precision, and returns the results along with clear metrics on how it found the answer.

Agent Taxonomy
Not all queries are created equal. We use different agents to handle different levels of complexity:Why Agentic Retrieval Matters
Standard vector search works great when a query maps directly to a single memory. However, real-world questions are often “messy.”agent_mode is designed for scenarios that require:
- Multi-hop chains: Where Fact B can’t be found until you find Fact A.
- Relationship traversal: Jumping across entities (e.g.,
Person->Organization->Role). - Mixed constraints: Filtering by time, location, and role simultaneously in steps.
- Sufficiency checks: Ensuring the agent doesn’t stop until it actually has enough evidence.
The “Spouse” Problem (Multi-hop struggle)
Imagine asking: “What is the current company of the spouse of the CEO of Acme?” A standard search might over-focus on “Acme” and “CEO,” completely missing the spouse’s data because that entity hasn’t been identified yet.How MemMachine Fixes This
- Detection:
ToolSelectAgentsees the complexity and routes to a chain-based strategy. - Iteration:
ChainOfQueryAgentfinds the CEO first, identifies the spouse, and then searches for that spouse’s company. - Verification: At each step, the agent checks if it has enough info to move forward.
- Ranking: All gathered evidence is combined and ranked to give you the most relevant answer.
Setting
agent_mode=false (default) uses the standard EpisodicMemory path. This is faster for simple queries but may struggle with multi-step reasoning.Workflow Diagram
This diagram shows how our Intelligent Orchestration resolves these patterns by branching between standard and agentic paths: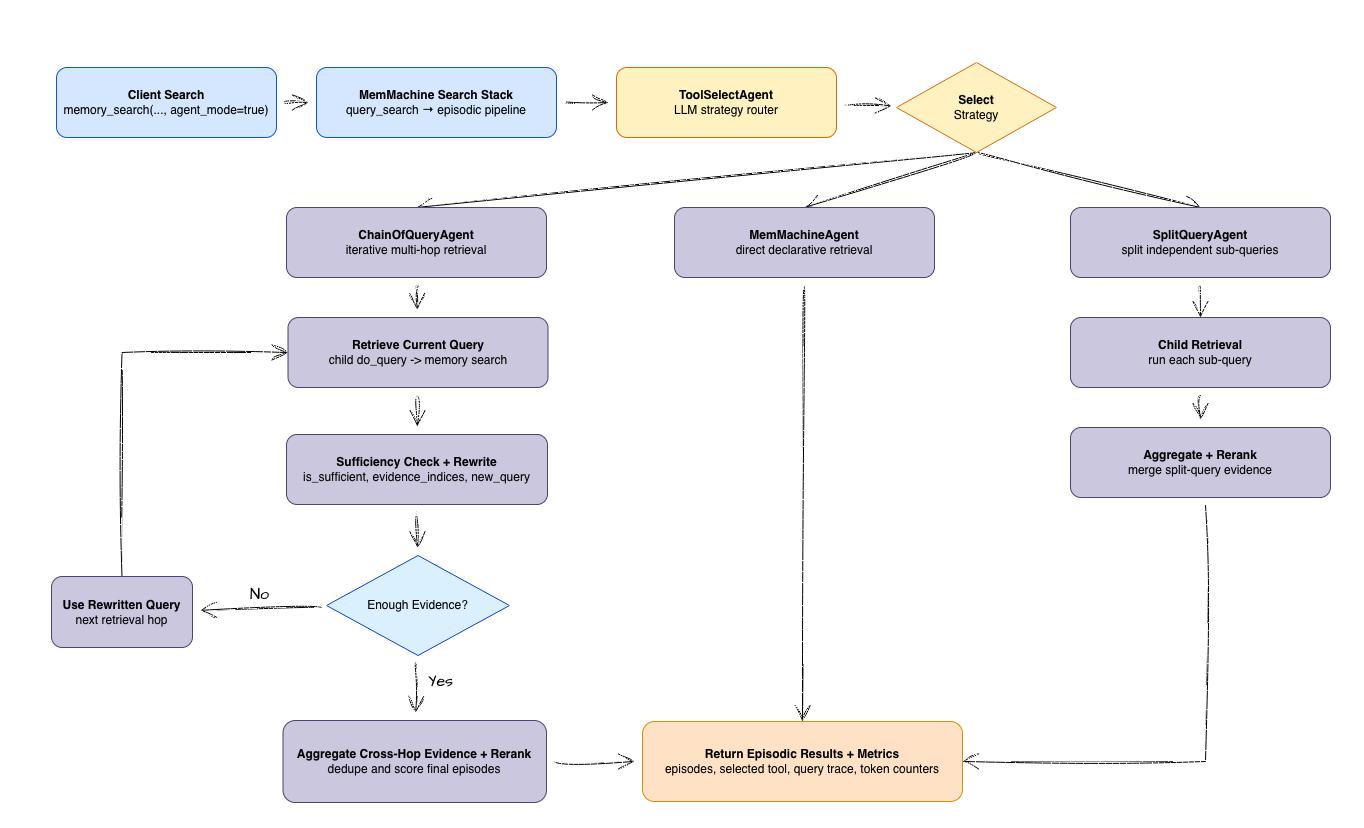
Configuration & Extension
You can fine-tune how these agents behave using theextra_params dictionary.